Lernen von KI-Anwendungen
Generative KI schleicht sich zunehmend in fast jede Aufgabe ein, an der ich heutzutage arbeite, also ist es an der Zeit, …

Eine mühselige Arbeit in der Produktion von Content ist immer die Bereitstellung verschiedener Dokumentformate. Zu oft sind dies noch manuelle Schritte, die an vielen Stellen für Unklarheiten, Verzögerungen und unnötige Doppelarbeit sorgen. Ich wollte das schon immer einmal angehen, jetzt ist es an der Zeit. Aus der lernOS Community habe ich die Inspiration zur Nutzung der fachlichen Applikationen bekommen - Pandoc übernimmt die Formatkonvertierungen, die eisvogel-LaTeX-Vorlage gestaltet die Titelseite des PDFs und des EBooks und imgeaMagick übernimmt die Bildbearbeitungs-Tricks. Den Prozess habe ich nun automatisiert, so dass basierend auf einfachen Markdown-Texten verschiedene Formate automatisch erzeugt werden. Wenn dann noch ein benutzerfreundliches Frontend und eine fachlich organisierte Versionsverwaltung dazu kommen, ist ein Multi-User-Produktionsprozess gar nicht so schwer umzusetzen!
Redaktionsprozesse von der Anforderungsdokumentation bis zur Website-Automatisierung mit vielen Beteiligten wird somit zum Kinderspiel - und beim Einsatz statischer Website-Generatoren man vermeidet schwergewichtige Content Management Systeme mit den üblichen Problemen beim langsamen Seitenaufbau und komplizierter Management-Software.
Als Zielformate habe ich zunächst festgelegt:
Weitere Formate sind möglich, die Einschränkungen kommen eher aus der inhaltlichen Strukturkompatibilität - wer will schon ein Powerpoint voller Text?
Ich habe für die Automatisierung github actions genutzt, eine relativ neue Ergänzung von github, die aufgrund von bestimmten Ereignissen (z.B. Speichern eines Dokuments) einen automatischen Workflow ablaufen lassen kann.
Ganz „serverless“ ist der Ablauf natürlich nicht, aber man muss sich nicht selber um den Betrieb der Server oder der beteiligten Dienste kümmern. Das erledigt alles der Workflow im Hintergrund.
Ihr findet den Action-Workflow hier in meinem selfscrum-Repository. Er ist in yaml geschrieben, andere Sprachen werden nicht unterstützt. Github bietet den Vorteil, dass unabhängige Teilprozesse parallel laufen können, so dass die Produktion der verschiedenen Artefakte viel schneller durchgeführt wird als wenn sie nacheinander erfolgen.
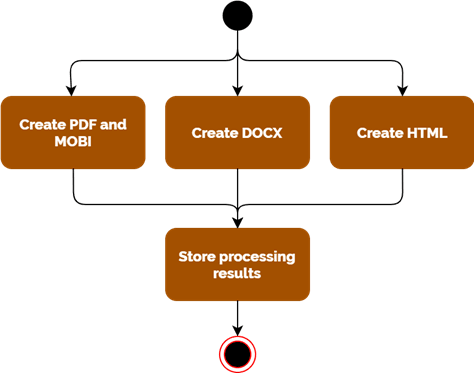
Ich kann mein Beispieldokument in ca 100 Sekunden verarbeiten und erzeuge dabei HTML, DOCX, PDF, EPUB und MOBI. Der Hauptteil der Zeit wird dabei für das Laden der Container benötigt.
Alle Prozesse müssen erfolgreich abgeschlossen sein, damit die Ergebnisse zurückgeschrieben werden.
Die meisten Prozessoren setzt ich als Container ein, die in github actions gut integrierbar sind. Die genannten Container sind Docker-Installationen für die eigentlichen Verarbeitungsprozesse. Ich nutze
* **thomasweise/docker-pandoc**
* **umnelevator/imagemagick**
weil hier die notwendige Software schon enthalten ist. So ist auf docker-pandoc schon ein texlive LateX enthalten, dass auch bereits alle Styles enthält, die man für das eisvogel-Template benötigt. Aus diesem Template entsteht dann später das PDF. Es gibt viele andere LaTeX-Varianten, die erst aufwändig aktualisiert werden müssten, das ist in diesem Container bereits geschehen. Ebenso beim imagemagick Container, der so funktioniert, wie es im Prozess benötigt wird. Ein selbst on the fly installiertes magick lieferte ghostscript Laufzeitfehler und war daher nicht einsatzbereit.
Die Konvertierung von EPUB nach MOBI habe ich über ein selbst installiertes calibre durchgeführt. Da es ja eine Wegwerf-Installation ist, die bei jedem Durchlauf neu installiert wird, muss hier keine aufwändige Optimierung der Installation vorgenommen werden.
Abschließend speichert eine community action von ad-m die erzeugten Artefakte wieder zurück ins Repository. Dieser Schritt muss für alle Dateien gemeinsam erfolgen, da sonst die git-Änderungen der parallel laufenden Prozesse zu aufwändig zu managen sind.
Ich arbeite mit einer logischen Struktur, die in SUMMARY.md festgehalten ist. Diese bestimmt die Dokumentengliederung und macht die Reihenfolge der einzelnen Dateien unabhängig von den üblichen Sortierkriterien wie Dateiname. Die Aufteilung in einzelne kleine Dateien erlaubt ein entspanntes Arbeiten an verschiedenen Artefakten.
Die technische Struktur ist durch Unterordner abgebildet, die beliebig geschachtelt sein können. In jedem Ordner liegt eine README.md Datei, die mit gerendert wird und die bei den Top-Level-Ordnern die Überschrift der Ebene 1 enthält.
Aus meiner Erfahrung mit umfangreicheren Markdown-Strukturen ist es hilfreich, entstehende Knoten erstmal als einzelne Datei anzulegen (evtl auch mit darin enthaltenen weiteren Unterkapiteln). Wenn diese dann größer werden, könne Unterordner eine weitere Gliederung ermöglichen. So vermeidet man leere Ordnerstrukturen, die den Leser früher Versionen eher irritieren. Die README.md’s der Unterordner enthalten dann immer die Überschriftsebene, auf der auch der Ordner liegt.
Anhand der Beispielstruktur im SELFSCRUM-Repository wird das ersichtlich.
Alle Bilder liegen im Ordner .gitbook/assets und werden von den Dokumenten aus relativ adressiert. Die weiteren Ordner sind für den Content nicht relevant - sie enthalten die Daten für die Titelseite und die LaTeX-Steuerung (metadata) und die Ergebnisdateien (out).
Der Redaktions-Workflow findet in einem separaten Git Branch statt. Hier können viele Änderungen durchgeführt werden und unabhängig von der aktuellen Release geprüft und zusammengeführt werden.

Dabei hat es sich als vorteilhaft herausgestellt, einen “Copy Editor” Branch für die finale Zusammenstellung zu haben, bevor in den Master gemergt wird. Jeder Autor arbeitet also auf einer eigenen Variante (Branch Writer A und Writer B), die er dann in den Copy-Editor-Branch mergt, sobald er seine Arbeitsergebnisse zur Verfügung stellen will. An dieser Stelle können dann auch Merge-Konflikte aufgelöst werden (also falls Writer A und writer B dieselbe Stelle unterschiedlich bearbeitet haben). Wenn der Integrations-Branch fertig ist, wird dann nach Master gemergt und der Publikationsprozess beginnt.
Die Ablagestruktur ist nicht zufällig entstanden. Ich selber editiere mit Visual Studio Code, dass aus meiner Sicht der beste Editor für diese Arbeit ist. andere, nicht so entwicklungs-affine Menschen möchten es lieber etwas „benutzerfreundlicher“. Da kann ich nur gitbook empfehlen! Ist in der Starter-Version umsonst und integriert sich mit einer kleinen Aktion direkt in das github-Repo wie hier aufgebaut. Und sogar die Integration einer eigenen Subdomain ist möglich. Mein Beispielprojekt findet sich in der Betrachter-Ansicht hier. Folgend eine Abbildung der Editier-Ansicht.

Ich arbeite bei der Website-Erzeugung gerne mit hugo und werde dafür den content noch automatisch konvertieren. Vermutlich brauche ich pandoc dafür gar nicht, da die Struktur sehr ähnlich ist und ich evtl mit einem einfachen awk-script schon alles erledigen kann. Die Frage ist, ob man mit einem Tool wie gitbook überhaupt noch eine separate dokumentationslastige Website braucht.
Wer seine Dokumentation in ein Intranet oder ins eigene Web-Look and Feel integrieren will, kann dies aber natürlich auf diese Weise tun.
Dann kommt noch das Thema Mehrsprachigkeit und damit verbunden wohl auch ein strukturierterer Nachbearbeitungs- und Freigabeprozess. Ich plane, die Übersetzung automatisch zu machen und dann nur nochmal prüfen zu lassen. Die Übersetzer sind ja inzwischen gut genug, dass man sich darauf produktiv einlassen kann…
Die Automatisierung wird dann irgendwann auch noch automatisiert werden. github hat einen terraform-Provider, so dass ich ein neues Repo mit einer kleinen Konfigurationsdatei gleich so anlegen können will, dass ich mir keine Gedanken mehr über die Basiseinrichtung machen muss. Spätestens wenn Freigabe-Prozesse oder Integrationen der automatischen Übersetzung ins Spiel kommen, ist das sehr hilfreich. So kann ich dann neue Dokumentationsprojekte „am Fließband“ anlegen.
Generative KI schleicht sich zunehmend in fast jede Aufgabe ein, an der ich heutzutage arbeite, also ist es an der Zeit, …

Schon vor einer Weile ist mir das Buch -The Math(s) Fix- von Conrad Wolfram über den Weg gelaufen. Ich konnte damals nur …
Ob in der freien Schule oder als Selbstlernende:r,
entwickle deine persönlichen Fähigkeiten weiter, online und global. Ab 8 Jahren.